The PostgreSQL Locking Trap That Killed Our Production API (and How We Fixed It)
TL;DR
A simple ALTER TABLE statement can bring down your production infrastructure if you’re not careful.
This is the story of me waking up to production alerts while working on totally unrelated tasks (building slides for some business stuff),
getting bamboozled, instinctively blaming most recent production infrastructure change and eventually figuring out how deep the rabbit hole goes.
Here is the chain of events if you are skimming through:
- Google Cloud monitoring policy triggered on database error threshold breach
- Production APIs showing high latency and intermittent timeouts
- Initially blamed the recently deployed database read replicas as the root cause
- Stopped replication, restarted database instance for service restoration
- Quickly figured out the issue reappeared on high load
- Manually deleted PostgreSQL replication slot from primary database instance
- Manually deleted read replica instances (non-critical), hoping against hope
- Raised support ticket with Google cloud
- Slow query analysis showed multiple pending
ALTER TABLE ..queued up - Shocked realizing that we ran an
ALTER TABLE ..on a very large and read heavy table even with multiple guardrails in place - Killed all
ALTER TABLE ..queries and blocked all schema migration in production till a permanent fix was implemented - All services restored. FINALLY!
- Identified the root cause as a lock contention issue across multiple background job workers, schema migrator and long running transactions
- Isolated application level locking from business logic tables to a common locks table to avoid lock contention with
ALTER TABLEwhich in turn locks the entire table - All Services restored including internal release related services
The Incident: When Everything Just… Stopped
It started with Google Cloud monitoring alerts triggered on database error threshold being breached. Saw a whole bunch of error logs
with Context cancelled by user statement.
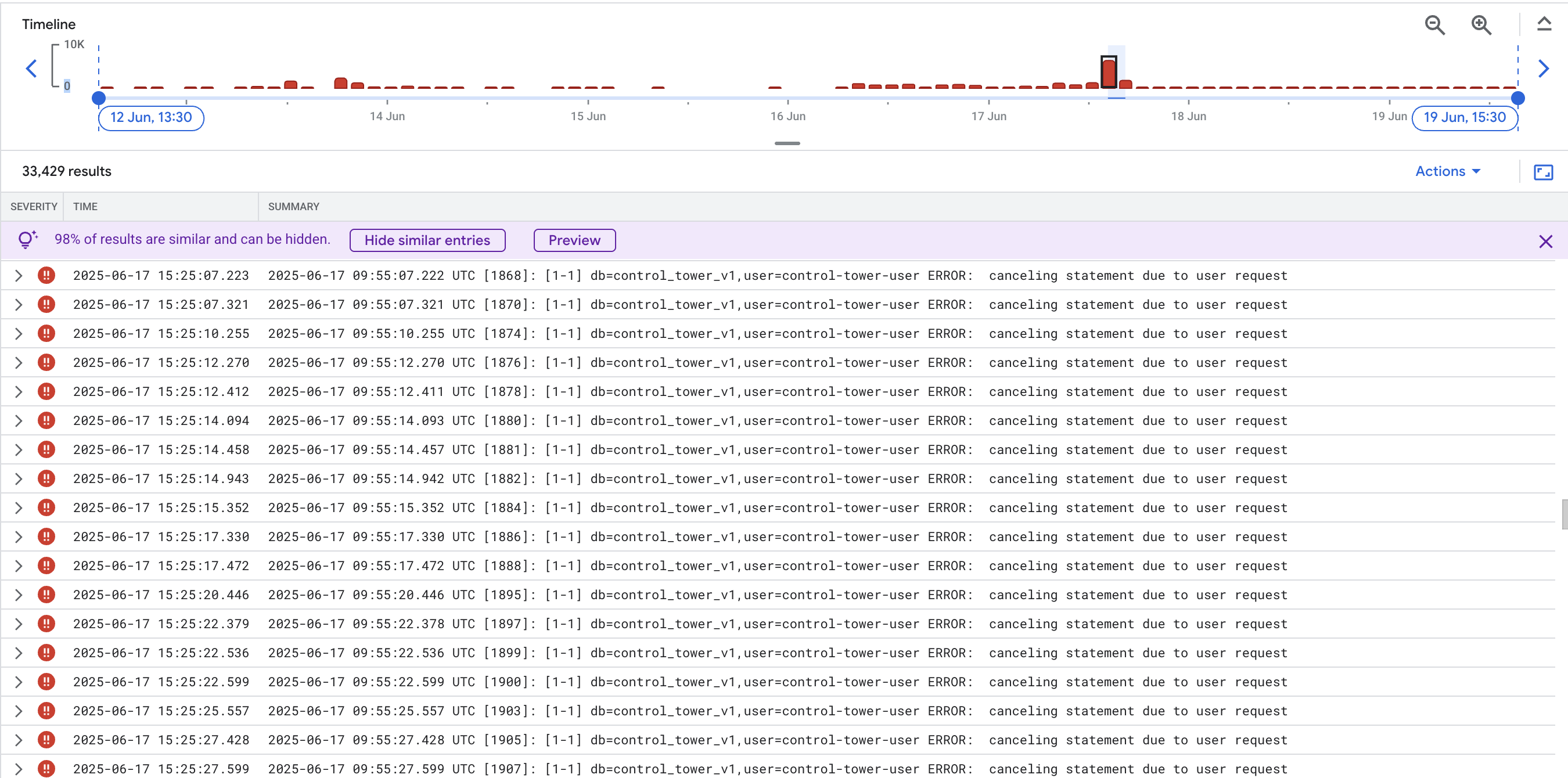
The immediate reaction (panic) was to blame the recently provisioned read replica for the production database instance. This was done to safely execute internal analytical queries with Metabase, a non-critical internal service. My response was
- Stop the replication in the replica instance using Google Cloud console
- Restart the primary database instance hoping that any performance issues due to replication would be resolved
This temporarily restored the services but the errors quickly returned. It also correlates with time of the day when our usage is at its peak. My mind correlated this by making a hypothesis that we introduced a new query that may have a missing index leading to a table scan. But I could not validate this hypothesis by looking at CPU, memory and IO metrics of the primary database instance.
In fact, we did not see any replication lag during the last 24 hours. This made me question my hypothesis of the issue caused by read replicas. Even though that was the most recent infrastructure change that I could confirm looking at our Terraform repository commit history. Finally decided its time to dig deep because of:
- No CPU / memory / IO wait metric anomaly for primary database instance
- No replication lag in read replicas
- Binary log size (storage) started increasing on primary when replication was stopped. This is expected due to active replication slots in the primary.
- Manually deleted PostgreSQL replication slots from primary database instance
- Even deleted the replicas assuming some weirdness with Google CloudSQL and its internal high availability configuration
Find the slots used by replicas.
SELECT * FROM pg_replication_slots;
Delete the slot
SELECT pg_drop_replication_slot('$slot_name');
The Real Culprit: Lock Contention Hell
It was clear that reverting recent changes is not going to fix the issue. It was time to dig deeper. Retrospectively, I think I planned to do the following:
- Identify long running or expensive queries
- Identify the root cause of the expensive queries
- Optimize them by rewriting them or using appropriate indexes
The following query was used to list all active queries and sort them by the query age. This gives a view of the long running queries along with the PID and other information required to kill the query if required.
SELECT datname,
usename,
application_name as appname,
pid,
client_addr,
state,
now() - backend_start as conn_age,
now() - xact_start as xact_age,
now() - query_start as query_age,
now() - state_change as last_activity_age,
wait_event_type,
wait_event,
query
FROM pg_stat_activity
WHERE state <> 'idle'
ORDER BY query_age DESC
LIMIT 100;
The output showed:
- Multiple
SELECT .. FOR UPDATEstyle locks waiting to be acquired - Multiple
ALTER TABLE .. ADD COLUMNstatements queued up - Multiple
INSERT .. ON CONFLICT DO NOTHINGstatements queued up
The most interesting bit is, all these queries were waiting to acquire a lock on the malware_analyses table. This is the table where we store OSS package scanning jobs powering SafeDep vet, updated by background job workers and queried by a user facing API. At this point, I was fairly sure it is a lock contention issue but wanted to confirm it before taking any action, especially since I already exhausted myself by reverting infrastructure changes as panic response.
The Perfect Storm: How It All Went Wrong
Lets have a quick look at the components that act on the malware_analyses table and how they interact with each other. The system consists of the following logical components:
- Submission API that is idempotent and can be retried without creating duplicate jobs
- Background job workers that actually execute an OSS package analysis job with a timeout of 15 minutes
- Query API that is used to fetch the status and results of a job by its job identifier
We also have a schema migrator built as part of our application development framework, which internally executes GORM migrations with additional safety checks that guarantee timeouts, global locks, audit logs and more.
Submission API
Our API framework is built to execute a business logic (service layer) in transaction by default for consistency unless explicitly opted out by the service specification. We generally opt out of transactions only for read-only operations. In case of the submission API, the service logic does the following in a transaction:
- Check if the job already exists in the database
- Create a new job record in the database if it does not exist
- Create a background job to execute the OSS package analysis job (transactional consistency)
- Return the job identifier to the client
Note: The submission API is idempotent which requires attempting to read a row from the malware_analyses table to check if the job already exists before performing an INSERT operation. The table uses unique index constraints to guarantee idempotency even when there is a race condition. This means, INSERT .. cannot be concurrent.
INSERT into tables that lack unique indexes will not be blocked by concurrent activity. Tables with unique indexes might block if concurrent sessions perform actions that lock or modify rows matching the unique index values. Ref
Package Analysis Business Logic
The background job workers execute the OSS package analysis job with a timeout of 15 minutes. The job is executed in a transaction and the following steps are performed:
- Acquire a row-level lock on the
malware_analysesrecord to prevent multiple workers from executing the same job concurrently - Execute a long running RPC call to an external service that takes up to 5 minutes to complete
- Update the job record in the database
Example code snippet from the background job worker:
// This code was holding row-level locks for ~60 seconds
func (j *malysisAnalyzePackageJobExecutor) Execute(ctx ectx.C, job MalysisAnalyzePackageJob) error {
tx := ctx.DB()
// This acquires a row-level lock with SELECT ... FOR UPDATE
var analysis models.MalwareAnalysis
err := tx.Clauses(clause.Locking{
Strength: "UPDATE", // Row-level lock
Options: "NOWAIT",
}).Where("external_id = ?", job.AnalysisID).First(&analysis).Error
// This RPC call typically takes 30-60 seconds
err = async.RpcInvokeWithNamespace(ctx, j.client, j.config.ClientNamespace,
procedureName, request, &response, async.RpcCallOptions{
Timeout: 5 * time.Minute,
})
// Still holding the lock while we update
err = tx.Save(&analysis).Error
return nil
}
Schema Migration
The schema migrator is a tool that we use to safely apply schema changes to the database. In this particular case, following was the schema change that triggered the issue:
// MalwareAnalysis is the model for serving Malysis v1 API.
type MalwareAnalysis struct {
GlobalModel
@@ -66,6 +87,12 @@ type MalwareAnalysis struct {
// Set time for when the is_malware field was set to false
WithdrawnAt *time.Time `gorm:"index"`
+
+ // Package publishers
+ Publishers datatypes.JSONSlice[PackagePublisher] `gorm:"type:jsonb;default:'[]'::json;index:,type:gin"`
+
+ // Package download statistics
+ Downloads datatypes.JSONType[PackageDownloads] `gorm:"type:jsonb;default:'{}'::json;serializer:json;index:,type:gin"`
}
This schema change adds two new columns to the malware_analyses table along with adding indexes on them.
This translates to the following SQL statement:
ALTER TABLE malware_analyses ADD COLUMN publishers JSONB;
ALTER TABLE malware_analyses ADD COLUMN downloads JSONB;
CREATE INDEX idx_malware_analyses_publishers ON malware_analyses USING gin (publishers);
CREATE INDEX idx_malware_analyses_downloads ON malware_analyses USING gin (downloads);
Thing to note here:
ALTER TABLE .. ADD COLUMNstatement needs anAccessExclusiveLockon the table even though its just a table metadata update- The index creation is a separate operation that, by default, needs an
AccessExclusiveLockon the table unlessCONCURRENTLYis explicitly specified
PostgreSQL supports building indexes without locking out writes. This method is invoked by specifying the CONCURRENTLY option of CREATE INDEX. Ref
The Lock Hierarchy That Kills
Here’s what PostgreSQL’s documentation tells us about AccessExclusiveLock:
“Conflicts with ALL other lock modes. Guarantees that the holder is the only transaction accessing the table in any way.”
Now that we saw the lock hierarchy, we can see there are multiple contenders that contributed to the incident by holding locks or trying to lock the entire tabling by requesting AccessExclusiveLock.
The root cause of the issue is the following sequence of events:
- Background jobs start - Acquire row-level locks on
malware_analyses - Schema migration starts - Waits for
AccessExclusiveLockonmalware_analyses - New Submission API requests arrive - Queue behind the
ALTER TABLEwaiting for table access - Cascading failure - All API (app) server Go routines blocked on database calls
- System death - API becomes unresponsive, not just for impacted tables but for all API endpoints
The Fix: Isolate Locks
Two things were clear so far:
- Long running transactions are toxic - The best practices are right!
- Schema migration on large and busy tables are VERY VERY risky
Lets ignore the fact that we tried creating an index on a large table, we can mitigate it by updating our schema migration process to leverage maintenance window and concurrency primitives offered by PostgreSQL. But this incident can repeat again even for a harmless ALTER TABLE .. ADD COLUMN statement that only modifies table metadata. This is because, the ALTER TABLE .. will wait for AccessExclusiveLock on the table even though its just a table metadata update. Row level locks held by background job workers makes the table slow and risky for schema changes.
Locking is however an application primitive that we need. We have two options:
- Use an external service like Redis for locking
- Isolate locking from business logic tables to a common locks table
While blogs and other common wisdom points to [1], we decided against it because it introduces additional complexity of serializing locks and data access across multiple services ie. PostgreSQL and Redis. We decided to continue leverage PostgreSQL for resource (row) level locks but isolate them from business logic tables that may be changed as and when required. Instead, we decided to introduce a common resource_locks table that will rarely require schema changes because it offers a single primitive ie. lock a row by resource_name and resource_id.
Before: Direct Table Locking
Service level, adhoc locking pattern before the incident:
// DON'T DO THIS - locks business logic table
var analysis models.MalwareAnalysis
err := tx.Clauses(clause.Locking{
Strength: "UPDATE",
}).Where("external_id = ?", analysisID).First(&analysis).Error
After: Common Lock Table
Common resource locking API for use by the service layer. While currently it leverages PostgreSQL backend for locking, the API offers abstractions for us to keep options open for future.
// Create a dedicated locking table
type ResourceLock struct {
GlobalModel
ResourceName string `gorm:"not null;uniqueIndex:idx_resource_locks_resource_name_id"`
ResourceID string `gorm:"not null;uniqueIndex:idx_resource_locks_resource_name_id"`
// .. Other metadata
}
// Use it for serialization
func WithResourceLock(db *gorm.DB, resource LockableResource, heldBy string, fn func(*gorm.DB) error) error {
return db.Transaction(func(tx *gorm.DB) error {
// Create a lock in the resource_locks table
// Acquire a row level lock on the resource_locks table
// Execute the business logic
return fn(tx)
})
}
The New Pattern
Finally, the business logic can be executed without holding any locks on the business logic table and leveraging the common resource locking API.
// Now business logic locks are isolated
return models.WithResourceLock(ctx.DB(), analysisJob, "analyze_package_job",
func(tx *gorm.DB) error {
// Business logic here - no locks on malware_analyses table
var analysis models.MalwareAnalysis
err := ctx.DB().Where("external_id = ?", job.AnalysisID).First(&analysis).Error
// Long-running RPC call
err = async.RpcInvokeWithNamespace(...)
// Update without row locks
err = tx.Save(&analysis).Error
return nil
})
Deploying the Fix
So far so good. We have a fix in place. But there are challenges with deployment because it requires schema changes and background job workers to be restarted. We were reluctant to execute schema changes in production without a proper maintenance window but we also needed to unblock releases that required schema changes. So we roughly took the following steps:
- Paused all background jobs for the queue that was running the OSS package analysis jobs to avoid any row level locks on the
malware_analysestable - Waited for all existing jobs to complete and verified no queued queries in the database
- Deployed the fix to production
- Applied the schema changes for common locks table
- Restarted all background jobs for the queue
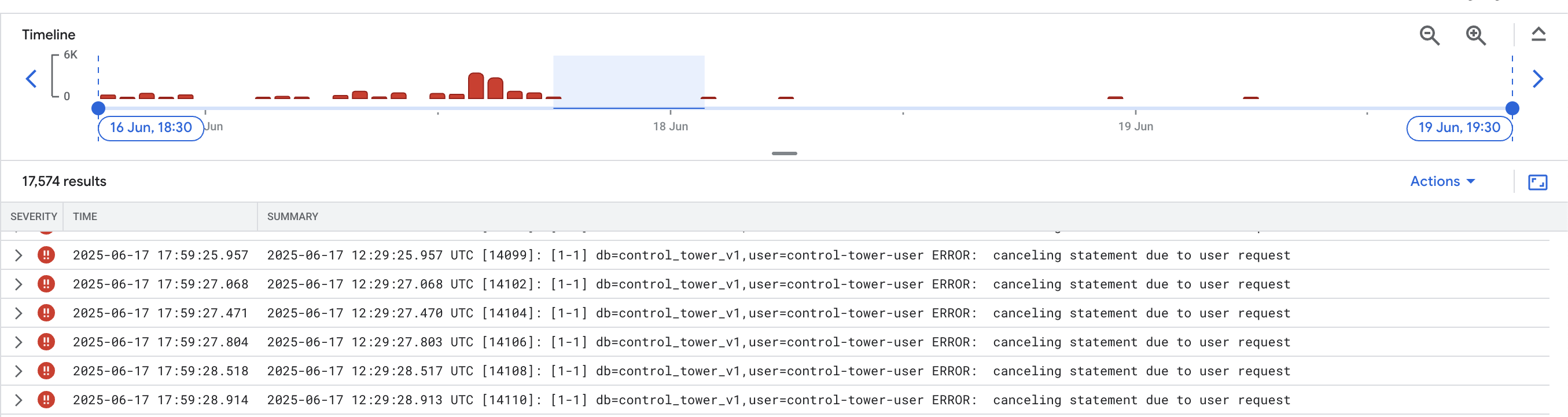
Aha! thats how it looks like after the fix, with usual schema migration and background job workers running again.
The Key Insight: Lock Isolation
The breakthrough was realizing that serialization requirements and business data storage are orthogonal concerns. You don’t need to lock the users table to ensure only one password reset email goes out. You don’t need to lock the orders table to prevent duplicate payment processing. You need a coordination mechanism that’s separate from your data storage. This ensures both application queries and schema management operations are not blocking by long held locks which may be required by the business logic (service layer).
The Real Lesson
This isn’t about PostgreSQL being bad or Go being bad or our architecture being bad. This is about the fundamental tension between consistency requirements and availability requirements in distributed systems. The CAP theorem suddenly seems more real, it shows up in your production database unexpectedly when you are trying to add a column and your API dies.